Dans la première partie, nous avons expliqué le « pourquoi » de cette opération. Maintenant, voyons le « comment ».
Nous allons voir en détail le déroulement d’un repair depuis l’exécution de la commande « nodetool repair test1 » (« test1 » étant un keyspace contenant une unique table de faible volume : table1). Soyez averti : les logs de Cassandra sont très verbeux et vous informent de bien plus de choses qu’il vous faut (1). Il est nécessaire de trier. C’est pour cela que le jeu de test est si limité. Pour qu’on s’y repère (2).
– Démarrage :
"StorageService.java: Starting repair command #1, repairing 768 ranges for keyspace test1 (parallelism=SEQUENTIAL, full=true)"
Si nous avions utilisé « nodetool -par repair test1 », nous aurions lu « parallelism=??? »
– Définition de la portée de la tâche :
"[AntiEntropySessions:1] RepairSession.java repair #c1f58d50-9db7-11e6-931b-e700f669bcfc new session will sync /127.0.0.3, /127.0.0.1, /127.0.0.2 on range (-5682128852645779623,-5646691764131133958] for test1.[table1]"
- « RepairSession.java » : Thread en charge
- « range… » : information utile si vous rencontrez un problème sur un intervale. Certaines commandes acceptent de travailler sur un intervale particulier. De même, la ligne indique l’adresse des nœuds possédant des réplicats. Notre exemple est un cluster minimum (3 noeuds) mais la liste peut être bien plus longue, surtout si vous êtes plusieurs datacenters et facteur de réplication.
– Handshake : tout le monde est là ?
"HANDSHAKE [INFO-/127.0.0.2] 2016-10-29 11:12:04,022 OutboundTcpConnection.java:488 - Handshaking version with /127.0.0.2" "INFO [HANDSHAKE-/127.0.0.1] 2016-10-29 11:12:04,024 OutboundTcpConnection.java:488 - Handshaking version with /127.0.0.1" "INFO [HANDSHAKE-/127.0.0.3] 2016-10-29 11:12:04,026 OutboundTcpConnection.java:488 - Handshaking version with /127.0.0.3"
Si un nœud ne répond pas, c’est l’échec:
"[2016-10-29 11:50:30,001] Repair session 2032f8d0-9dbd-11e6-9b83-e700f669bcfc for range (-5682128852645779623,-5646691764131133958] failed with error java.io.IOException: Cannot proceed on repair because a neighbor (/127.0.0.1) is dead: session failed"
C’est logique : comment réconcilier des données à leur dernière version s’il y a risque qu’elle soit connue du nœud absent uniquement ? (Si ! Cette phrase est compréhensible !). Il faut d’abord s’occuper de ce nœud indisponible.
Les préliminaires étant accomplis, l’opération se poursuit.
– Demande et récupération des arbres de Merkel vers le nœud coordinateur :
"[RepairJobTask:3] RepairJob.java repair #c1f58d50-9db7-11e6-931b-e700f669bcfc requesting merkle trees for table1 (to [/127.0.0.1, /127.0.0.2, /127.0.0.3])" "[AntiEntropyStage:1] RepairSession.java repair #c1f58d50-9db7-11e6-931b-e700f669bcfc Received merkle tree for table1 from /127.0.0.1" "[AntiEntropyStage:1] RepairSession.java repair #c1f58d50-9db7-11e6-931b-e700f669bcfc Received merkle tree for table1 from /127.0.0.2" "[AntiEntropyStage:1] RepairSession.java repair #c1f58d50-9db7-11e6-931b-e700f669bcfc Received merkle tree for table1 from /127.0.0.3"
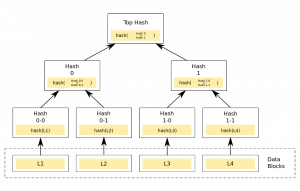
Exemple d’arbre de Merkle
Un « arbre de Merkle » est une construction mathématique permettant de résumé un grand volume d’informations. Ici, il sert à comparer les morceaux de tables entre eux. Pour faire simple : prenez une table locale et la même sur un autre nœud. Coupez chacune en deux parties et calculez un hash : sont-ils identiques ? Si oui, inutile d’aller plus loin : passez à la table suivante. Si non, les deux premières parties sont elles identiques ? Si oui, la différence se situe dans la seconde. Découpez ainsi chaque niveau jusqu’à cibler celui où se trouve la différence puis échanger les informations (en vous basant sur le timestamp) afin de propager celle qui est la plus à jour.
En lisant ces quelques lignes, vous imaginez le travail que cela demande au niveau de chaque nœuds, pour chaque partitions de chaque tables. C’est cette partie qui explique la consommation CPU et les multiples problèmes (nous en verrons quelques uns dans la troisième partie) lors de son exécution.
C’est ici que se paie la dette de mise à jour consentie pour obtenir les performances, évoquée dans la première partie de cette article. Du coup, ça fait un peu mal.
– après calcul des différences, synchronisation des données :
C’est pourquoi il faudrait appeler ça « resync » plutôt que « repair » mais il vrai que l’on répare des déchirures dans l’intégrité des données. Si vous êtes l’âme d’un poète, vous pouvez vous représenter la scène avec Arachné reprisant délicatement une de ses tentures. La vérité serait plus proche d’ouvriers vérifiant l’étanchéité des grosses bâches recouvrant une pile de déchets toxiques mais une légère illusion mythologique peut aider à passer la journée.
Mais trêve d’antiques digressions…
"[AntiEntropySessions:2] RepairSession.java repair #c2152340-9db7-11e6-931b-e700f669bcfc new session: will sync /127.0.0.3, /127.0.0.1, /127.0.0.2 on range (-5135847817702162648,-5127674545674473449] for test1.[table1]"</pre> "[RepairJobTask:3] Differencer.java repair #c1f58d50-9db7-11e6-931b-e700f669bcfc Endpoints /127.0.0.1 and /127.0.0.2 are consistent for table1" "[RepairJobTask:2] Differencer.java repair #c1f58d50-9db7-11e6-931b-e700f669bcfc Endpoints /127.0.0.1 and /127.0.0.3 are consistent for table1" "[RepairJobTask:1] Differencer.java repair #c1f58d50-9db7-11e6-931b-e700f669bcfc Endpoints /127.0.0.2 and /127.0.0.3 are consistent for table1"
– fin de la synchronisation d’un intervale :
"[AntiEntropyStage:1] RepairSession.java repair #c1f58d50-9db7-11e6-931b-e700f669bcfc table1 is fully synced" "[AntiEntropySessions:1] RepairSession.java repair #c1f58d50-9db7-11e6-931b-e700f669bcfc session completed successfully"
– Fin de la session de réparation : une série de lignes de ce type :
"INFO [Thread-6] StorageService.java Repair session cb01fd20-9db7-11e6-931b-e700f669bcfc for range (-5682128852645779623,-5646691764131133958] finished" "INFO [Thread-6] StorageService.java Repair session cb02c070-9db7-11e6-931b-e700f669bcfc for range (7941844116376061367,7951035744647025045] finished" (...) "INFO [Thread-6] StorageService.java Repair session cc8a98f0-9db7-11e6-931b-e700f669bcfc for range (-2948414265502274397,-2948097630674812353] finished"
Et Cassandra enchaîne sur le segment suivant.
Dire que le journal de log est verbeux est un euphémisme. Cassandra – comme d’autres produits de cette génération – vous raconte ce qu’il fait en long, en large et en travers. Le fichier system.log est une source d’information précieuse qui demande du temps avant de pouvoir être exploité.
Le détail des opérations exposé précédemment peut vous paraître long mais gardez à l’esprit qu’il couvre une réparation séquentielle d’une petite table, dans un petit keyspace, réparti sur trois nœuds. Nous pourrions vous détailler la même opération sur un cluster de trente nœuds, découpé en quatre datacenters, pour vous donner un aperçu du travail qui vous attend si d’aventure vous devez analyser ce genre de plate-forme.
Investir dans les outils tels que « dsh » ou « pssh » vaut largement l’effort.
Pour suivre l’avancée des réparations, si vous êtes *vraiment* curieux ou pressé par le temps, vous pouvez comparer le « range » indiqué dans les messages :
"new session will sync /127.0.0.3, /127.0.0.1, /127.0.0.2 on range (-5682128852645779623,-564669176413113"] for test1.[table1]"
Avec ceux listés pour le keyspace en cours :
nodetool describering test1 | grep "-5682128852645779623,-564669176413113" TokenRange(start_token:-5682128852645779623, end_token:-5646691764131133958, endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
Ça vous donne idée mais c’est franchement pas pratique.
« Nodetool compactionstats -H » retourne des informations incomplètes. Vous y verrez des lignes « Validation » et des durées de « 00:00:00 ». Pas très intéressant. Au moins, vous saurez si une opération est en cours.
« nodetool netstats » liste les transferts (« streams ») en cours. Malheureusement, pour les réparations comme pour les intégrations de nœuds, l’information est difficile à exploiter directement. Autant de lignes que de fichiers transférés, multipliées par le nombre de partenaires. Au moins pouvez-vous voir s’il y a des sessions bloquées ou non :
Mode: NORMAL Not sending any streams. Read Repair Statistics: Attempted: 0 Mismatch (Blocking): 0 Mismatch (Background): 0 Pool Name Active Pending Completed Dropped Commands n/a 0 768 0 Responses n/a 0 12417 n/a
Ici, tout est normal.
Pour finir, dans OpsCenter, les réparations apparaissent dans la rubrique « activités », « repair of keyspace.table » et un pourcentage de complétion. Là encore, ce sont des chiffres à prendre comme une indication globale. Toujours mieux que de ne rien savoir.
(1) un peu comme une chaîne d’informations en continu.
(2) « repair », « repère », on sent la personne d’esprit derrière le clavier, non ?