Résumé de l’épisode précédent: à la recherche d’information sur l’activité d’un cluster Cassandra, nous avons commencé par présenter les différentes commandes système à utiliser puis nous avons exposé plusieurs méthodes pour les rendre globales, c’est à dire pour les appliquer à toutes les machines ou à une partie seulement. A part cet aspect distribué, la démarche était celle à avoir sur une machine isolée.
Dans cette deuxième partie, nous allons voir l’utilitaire Nodetool (présent dans chaque installation Cassandra) et les options qui permettent de répondre à la question : « Cassandra, dis-moi, comment te sens-tu ce matin ? ».
La principale difficulté dans ce genre d’architecture est de bien cerner la portée des commandes. Certaines vont couvrir la totalité du cluster, d’autres vont tenter de répondre à une question globale mais avec des informations locales (exemple : nombre de lignes dans une Column Familly) et d’autres encore fournissent uniquement des informations locales. Et parfois, parce que après tout pourquoi pas, c’est un peu des deux.
Nous allons donc partir du périmètre le plus large (cluster) à celui le plus restreint (nœud). Nous ferons temporairement l’impasse sur les outils spécifiques à Java même s’ils représentent souvent le seul moyen de réellement comprendre ce qui se passe : c’est un sujet à part, suffisamment riche pour qu’il bénéficie de son propre article.
Et, naturellement, nous allons uniquement voir l’aspect « ligne de commande » pour rester dans la continuité de la première partie… et aussi parce que OpsCenter (l’interface graphique de Datastax) devient payant à partir de Cassandra V3.0.
Remontons nos manches et allons-y : bonne lecture !
- La première chose à faire : nodetool status
… ou même, plus pratique « nodetool status –resolve-ip », qui vous affiche le nom des machines. A moins d’avoir un tableau de résolution de noms en tête, cela vous simplifiera la vie.
Exemple :
$ nodetool status --resolve-ip Datacenter: DC1 =============== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns Host ID Rack UN Machine1 422,42 GB 256 ? 7ac8aa08-e850-4457-9ab7-28576cf84600 RAC1 UN Machine2 467,66 GB 256 ? 6032aba3-9fae-4259-aefe-5dceb029bf2b RAC1 UN Machine3 355,77 GB 256 ? 801e0038-b5b1-4d21-a8d5-527adad6c377 RAC1

Trois qui partent, deux qui restent pour travailler (allégorie)
« UN » : « Up/Normal ». Tout est OK, le nœud est disponible. Les autres statuts que vous pourrez voir sont « DN » (« Down / Normal ») pour un noeud arrêté et « UJ » (« Up/Joining ») pour un nœud en cours d’intégration. Vous pourrez éventuellement voir un « L » pour « Leaving » si un nœud est en train de sortir.
« Load » représente la répartition du volume des données. Si vous constatez de gros déséquilibres, c’est un signe que vos partitions sont irrégulières, sans doute mal choisies. « Tokens » ne sert plus à grand chose depuis Cassandra 2.0 et l’introduction des Virtual Tokens. « 256 » est le défaut et convient la plupart du temps. Si vous tenez à cibler au maximum des partitions en limitant les échanges inter-nœuds, vous pouvez changer cette taille mais sachez que plus la valeur est faible, plus les tokens représentent de volume sur disque et donc plus les déséquilibres sont marqués. C’est pour ça que nous sommes restés sur la ligne parlant de la répartition des données. Tout est réfléchi.
« Host ID », l’identifiant unique du nœud, vous servira dans le cas de l’éjection d’un élément KO ou d’une réduction de la taille du cluster car il est demandé par la commande « nodetool removenode ».
Ces informations vous permettent de vous faire rapidement une idée de l’état général des membres du cluster.
Maintenant, admettons que tous les membres soient présents, que les données soient correctement réparties mais que la commande « uptime » lancée de manière distribuée montre une machine nettement plus chargée que les autres.
« Mais quel est donc ce tracas qui me saisit donc séant ? », vous dites vous intérieurement, sans doute moins poliment.
Voyons cela de plus près.
- L’activité local : nodetool compactionstats et tpstats
Une règle empirique : si les commandes systèmes montrent une forte activité disque, regardez si vous avez des compactions qui tournent. Si elles montrent de l’activité disque et de l’activité CPU, cherchez plutôt des repairs. Et si « repair » et « compaction » ne vous évoquent rien, vous n’êtes probablement pas dans la bonne catégorie (ni sur le bon blog).
Bien sûr, vous pouvez vous jeter sur le journal d’évènement du nœud (system.log, cassandra.log… selon votre configuration) mais celui-ci est très verbeux. Il existe des moyens plus simples, par exemple « nodetool compactionstats -H » :
$ nodetool compactionstats -H

« -H » : affiche des unités de grandeur « humanisées » (GB, MB…) plutôt que tout en bytes. Une facilité bienvenue lorsque vous devez lire des dizaines de lignes.

Cassandra, The Definitive Guide, Jeff Carpenter et Eben Hewitt, Ed. O’Reilly
« pending tasks » : il peut y en avoir des dizaines sans que cela soit un problème. Mais il est déjà arrivé, lors de repairs, que ce chiffre monte à plusieurs milliers. Si c’est le cas, et que cela ne baisse pas dans l’heure qui suit, Cassandra a un problème. Un « nodetool tpstats » devrait vous le confirmer. Nous allons y venir juste après mais juste une remarque perfide : vous aurez remarqué que l’en-tête mentionne « table » et non « column familly ». Une preuve supplémentaire que l’on s’éloigne progressivement de l’intransigeance NoSQL (pas de schéma, API Rest…) pour reprendre les éléments de l’ancêtre relationnel. Comme quoi, tout n’était pas à jeter… Tant que nous y sommes dans les digressions : dans le Cassandra Definitive Guide, 2nd Edition, Jeff Carpenter et Eben Hewitt évitent justement l’écueil de vouloir couper tout héritage du modèle relationnel et prennent la peine de cerner les points forts et les points faibles des deux approches. Une présentation équitable qui fait plaisir à lire et un ouvrage que nous vous conseillons (nous ne touchons aucune commission, c’est un authentique conseil gratuit).
Fin des parenthèses encadrant l’aparté : revenons à nos commandes.
Que le nœud soit chargé, c’est facile à voir. Mais est-il capable d’absorber cette charge ou bien est-il saturé ? C’est une question à se poser tout de suite après.
« nodetool tpstats » affiche les statistiques des différents Threads Java (plus exactement les « Threads Pool » – le « tp » de « tpstats » – puisque nous sommes dans une Architecture Orientée Événement) mais également le nombre de messages qui ont dû être abandonnés (« dropped ») par ce nœud (car ce sont des statistiques locales).
Exemple :
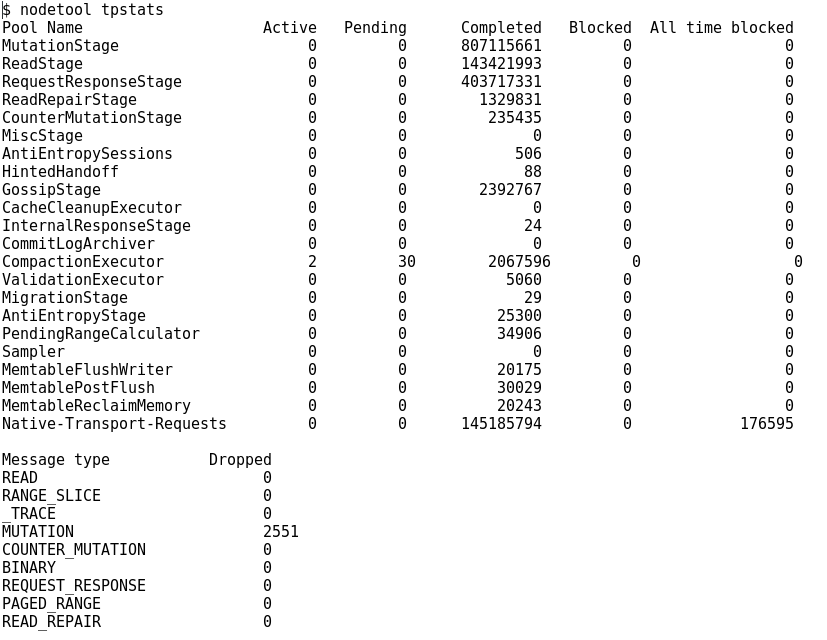
Note : les chiffres ci-dessus sont faux ! C’est proprement scandaleux mais nous n’avions que des statistiques excellentes donc il a fallu créer des chiffres plus parlant.
Vous obtenez un résumé de l’activité des pools Java depuis le lancement du nœud. Dans notre exemple, nous pouvons voir que la partie « compaction » est en pleine activité avec deux processus en cours et trente en attente. Mais aucun blocage n’est remonté. Le dernier paragraphe montre que des écritures (« mutations ») ont été refusées. Selon le temps depuis lequel Cassandra est lancé sur cette machine, le même chiffre peut être dérisoire (2154 depuis des mois…) ou signe d’engorgement (2154 depuis 15 minutes…). A mettre en perspective, donc.
- Autres utilisations de nodetool : gossipinfo et cfstats
Nous mettons les deux dans le même paragraphe bien que leur rôle soit totalement différent. Cependant, elles servent toutes les deux à obtenir des informations supplémentaires et sont intéressantes à connaître.
« nodetool gossipinfo » affiche un paragraphe de ce type pour chaque pair connu sur le réseau :
/www.xxx.yyy.zzz generation:1484230736 heartbeat:5756283 STATUS:79:NORMAL,-1018327793477189305 LOAD:5756229:3.89177391618E11 SCHEMA:4921727:d0cbc754-75e5-3f85-aed2-28e97137168d DC:8:DC1 RACK:10:RAC1 RELEASE_VERSION:4:2.1.13 INTERNAL_IP:6:www.xxx.yyy.zzz RPC_ADDRESS:3:www.xxx.yyy.zzz SEVERITY:5756282:3.121019124984741 NET_VERSION:1:8 HOST_ID:2:e4ad2026-9b85-4f46-87cd-64db27390904 TOKENS:78:hidden
« STATUS » et « LOAD » permettent de confirmer les informations ou de les collecter facilement pour une supervision. « SEVERITY » est plus difficile à cerner mais il donne une indication sur le niveau de confiance que le noeud local (celui où vous passez « nodetool gossipinfo ») accorde à chacun de ses partenaires. Une disparité de ce facteur (le « phi acturial factor », ou en tout cas en partie basée dessus) peut indiquer un problème de communication (jetez un œil sur les statistiques des interfaces réseaux : « netstat -i », s’il y a des erreurs). Cette commande nous semble en dire long sur la perception que les nœuds ont entre eux. Nous y reviendrons sans doute dans un prochain article mais il nous faut finir d’éplucher la documentation dont nous vous laissonsdifférents juger de la profondeur. Heureusement que toutes les commandes ne sont pas documentées de cette manière !
« nodetool cfstats« , de son coté, affiche les statistiques connues localement pour une column familly (une table, donc…) . Ça pourrait être simple mais il y a des pièges : les compteurs sont remis à zéro à chaque démarrage. Certaines informations sont des estimations (notamment le nombre de lignes total). Néanmoins, c’est une source d’informations primordiale sur l’état des tables, des performances et des fichiers locaux. Exemple (en ne conservant que les champs les plus imporants dans notre optique) :
$ nodetool cfstats nom_du_keyspace.nom_de_la_table_donc Keyspace: nom_du_keyspace Read Latency: 8.601128989065609 ms. Write Latency: 0.08028691977635084 ms. Pending Flushes: 0 SSTable count: 6 Space used (total): 96,78 GB SSTable Compression Ratio: 0.26280640696867547 Number of keys (estimate): 25685134 Memtable switch count: 720 Local read latency: 8,601 ms Local write latency: 0,081 ms Pending flushes: 0 Average live cells per slice (last five minutes): 0.5210796940833483 Maximum tombstones per slice (last five minutes): 936.0
Les temps de latence (« read/write » latency) locaux et globaux sont corrects et de valeurs proches. Il y a une nuance entre les deux car ils ne mesurent pas le même parcours (« libout » pour le premier, « libdata » pour le second) mais nous ne saurions en dire plus. Si vous pouvez nous expliquer, les commentaires sont fait pour ça. Pour le moment, nous allons en rester à une analyse basique « plus c’est rapide, mieux c’est ». Et lsur tout le cluster, les valeurs doivent être proches.
« SSTable count » représente le nombre de fichiers physiques locaux. Une valeur élevée (selon la nature des accès, cela peut signifier 30 à 100 fichiers…) indique qu’il est temps de faire une compaction ou qu’il y a un problème (lors de repairs en erreur, nous avons vu apparaitre des dizaines de milliers de fichiers pour la même table !).
« number of keys » : une estimation du nombre de lignes dans la table. Un point trivial à calculer en relationnel traditionnel mais délicat ici : un « select count(*)… » implique d’interroger tous les noeuds et peut surcharger le cluster. Le comptage des lignes dans Cassandra a généré une multitude d’articles. Nous vous conseillons celui-ci, qui traite le sujet en profondeur.
Exemple de Live Cells dans une Column Familly (une table, quoi…) Cassandra
« Average live cells / Maximum tombstones per slice » : une évaluation du rapport données actives / données périmées. Ce sont des chiffres difficiles à estimer. Par exemple, les tombstones (données supprimées / périmées) sont uniquement comptées à la lecture de la partition. Si vous ne faites qu’écrire, vous pouvez avoir un excellent ratio mais le disque dur remplit de données inutiles. Règle empirique n°2 : pas de tombstones sans feu. Si ce chiffre est élevé, cherchez un problème sur le modèle ou le déroulement des compactions.
Il y a également le champs « Space used by snapshots (total) » mais nous vous conseillons plutôt d’utiliser « nodetool listsnapshots » pour ce type de statistiques.
- Il y aurait encore beaucoup à écrire…
… mais les commandes présentées devraient vous permettre de déterminer si, oui ou non, vous avez un problème sur votre cluster. Nous n’avons fait qu’effleurer le sujet : il aurait fallu parler des indicateurs JMX, de la JConsole et des outils comme jstack pour identifier les threads Java, des tables du catalogue Cassandra et des traces activables… Autant de sujets protentiels pour l’avenir. Mais nous espérons vous avoir donné un aperçu des endroits où regarder et des indicateurs à surveiller.
Une dernière information : « nodetool help » pour l’aide générale et « nodetool help commande_qui_vous_interesse » pour l’aide spécifique à une commande qui vous intéresse. Cela permet d’éviter les pièges d’une syntaxe pas toujours cohérente.
Des problèmes ? des questions ? Exprimez-vous ! Les commentaires sont ouverts. Coquilles et fautes de grammaires sont notre lot quotidien : signalez-les nous à m.capello@dbsqware.com
Crédit photo : Wikimedia et Wikimedia également