Un titre de six mots seulement mais un vaste programme : après vous avoir rapidement présenté la pile ElasticStack, nous allons vous expliquer comment démarrer votre propre pile de test, du téléchargement des blocs jusqu’au premier graphique Kibana.
Cela risque d’être long alors, pour une fois et exceptionnellement, nous allons limiter autant que possible les digressions
C’est un sacrifice nécessaire. Car, même à notre modeste échelle, dans cette sphère confidentielle mais de qualité dans laquelle nous nous retrouvons toutes les semaines depuis bientôt six mois, nous sommes des journalistes, prêts à embrasser cette mission, ce sacerdoce même, afin de nous monter dignes des figures tutélaires qui nous ont précédées.

Pénélope Solette. Maurice Chevalier. Deux grandes figures du Journalisme Total Français.
Droit au but et sans circonvolutions alambiquées, attaquons le gras du sujet, si vous le voulez bien.
En prévision du jour hypothétique où nous trouverons un bon plug-in pour générer automatiquement une table des matières, voici les sections qui vous attendent (Ne cliquez pas dessus : ce ne sont malheureusement pas des liens !):
1) Présentation de la pile
2) Installation : choix préliminaires
3) Installation : les commandes
4) Configuration
5) Démarrage
6) Retour à Kibana et première visualisation
7) Conclusion
1) Présentation de la pile
Toutes les archives sont regroupées au même endroit : http://www.elastic.co . A l’heure où cet article est rédigé, la version globale est la 5.3.0.
Avantage : tous les composants de la pile évoluent de concert afin d’assurer leur compatibilité. Il est possible de faire évoluer chaque partie indépendamment et progressivement mais autant profiter de ce regroupement pour conserver des versions homogènes.
Note : nous avons fait une montée de 5.1.1 vers 5.2.2 puis 5.3.0 sans rencontrer de problème. Nous détaillerons ça dans un autre article, un jour.
Pour une bonne pile Elastic, vous avez besoin de trois ingrédients principaux :
- Elasticsearch : pour le stockage et l’indexation. C’est une architecture distribuée très simple à mettre en place car il existe un mécanisme d’auto-découverte des nœuds ainsi que d’équilibrage des données. Tous les champs qui lui sont confiés sont indexés avec Apache Lucene (version 6.5).
- Kibana : présentation des données, interface de recherche.
Une requête dans le langage d’Elasticsearch se rédige en Query DSL (« Domain Specific Language ») et se présente comme ceci :
Exemple Aussi Proverbial Que Cryptique
Exemple venu de ce site fort intéressant.
Une requête avec Kibana se construit à la souris, en choisissant les champs, en testant les visualisations (différents types sont proposées) et en les regroupant dans des tableaux de bord (« dashboards »). Un autre monde. Faites-en le votre, au moins pour commencer.
Avec ces deux seuls éléments, vous pouvez déjà collecter des données mais la plupart des utilisateurs préfèrent enrichir leur architecture.
- logstash. Vous pouvez vous le représenter comme un ETL souple et extensible. Il accepte en entrée différents formats de données et il est capable de les transmettre vers de nombreux types de sortie, tout en les transformant et en les étiquetant au passage à l’aide de greffons variés.
C’est le paradis de l’expression régulière ressemblant à une incantation de fin du monde.
Heureusement qu’internet existe et vous permet de trouver des expressions régulières toutes faites.
- Beats : c’est un ensemble de collecteurs déployés sur les sources de données. Certains sont fournis et maintenus par la société Elastic.co, d’autres par une mystérieuse « communauté ». Parmi les principaux :
– metricbeat : mesure les performances systèmes telles que mémoire et CPU. Mais également l’espace disque, les processus… Une vraie solution de monitoring à la manière d’un Nagios. Cependant, il va plus loin puisqu’il incorpore une série de modules plus précis : pour MySQL, PostgreSQL, HAProxy, ZOO Keeper… Un fichier de configuration global est fourni et il suffit de copier/coller le paragraphe qui vous intéresse pour surveiller un composant.
– packetbeat : extraction de données depuis une analyse de paquets réseaux. Nous ne l’avons pas testé en profondeur mais cela semble très puissant, au moins autant qu’un TCP dump + wireshark. Nous vous en reparlerons.
– filebeat : le plus simple à mettre en place mais aussi celui qui vous demandera le plus de travail. Filebeat surveille les fichiers de log. C’est tout. Mais il le fait bien : reprise en cas d’interruption, pré-filtrage avant d’envoyer les lignes, ajout de champs et d’étiquettes dès la source… Nous l’avons utilisé avec des logs Cassandra, PostgreSQL, système (/var/log/secure) et c’est l’outil idéal pour enfin pouvoir regrouper vos logs d’application au même endroit. Par contre, il faudra prendre le temps de maîtriser Logstash et son plugin Grok pour ne pas tout bourrer dans votre cluster Elasticsearch et vous plaindre après de ne rien retrouver. On vous fait confiance.
Un dernier composant, optionnel mais capital : X-Pack. C’est un module payant qui affecte ElasticSearch et Kibana en ajoutant la gestion des droits d’accès (login/mdp). Dans Kibana, il débloque également les options de monitoring, d’analyse graphique (au sens « Graph Databases ») et des informations générales plus complètes. C’est la seule partie payante de toute la pile. Selon votre choix, l’ouverture de votre plate-forme sera plus ou moins possible. Comme c’est un cas particulier, nous lui réservons un article spécifique.
2) Installation : choix préliminaires
Ce qui va suivre est une manière parmi d’autres mais elle présente un gros avantage pour nous : c’est celle que nous utilisons.
Sachez qu’il y a peu de pré-requis système : une JVM (7 ou 8) et deux paramètres noyaux pour ElasticStack : nofile et vm.max_map_count
Note importante : tant qu’il tourne avec une adresse locale (« loopback »), ElasticSearch ne remonte qu’un warning sur ces deux paramètres. Dès qu’une adresse ouverte est configurée, le programme se considère en production. Les warnings deviennent de vraies erreurs et il refuse de démarrer.
Autant évacuer le sujet tout de suite :
Pour modifier le « max open file ».
vi /etc/limits.d/31-elastic.conf
#<domain> <type> <item> <value>
votre_compte hard nofile 65536
votre_compte soft nofile 65536Pour modifier la taille « max vm.memory » :
sysctl -w vm.max_map_count=262144
Et modifier /usr/lib/sysctl.d/00-system.conf pour conserver le changement :
vm.max_map_count=262144
« sysctl -p » pour charger la configuration. .
Avant de vous lancer, réfléchissez deux minutes. Où allez vous installer les binaires ? Où seront les données ? Les fichiers de configurations ? Souhaitez-vous automatiser (avec Ansible, pas exemple) ou est-ce seulement une installation jetable ?
Notre choix :
- Installation manuelle et jetable (même si nous prévoyons d’utiliser Ansible dans le futur). Ce sera dans /opt/ELK. Un compte « elk » est créé pour l’occasion.
- Un répertoire pour les données ElasticSearch. Un point d’architecture intéressant : le dossier des données peut être partagé entre plusieurs instances locales car il contient des sous-dossiers par noeud. Cela facilite les déplacements.
- Nous laisserons les logs dans les dossiers d’installation bien qu’il soit plus propre de les ranger dans un emplacement dédié.
- Même remarque pour les fichiers de configuration. Cela simplifierait les montées de version mais cela compliquerait l’exemple.
- Pour masquer les numéros de version, chaque dossier de binaires aura un lien symbolique.
3) Installation : les commandes
Dans cette partie, rien de bien sorcier.
En root : créez les répertoires et donnez-en la propriété au compte « elk » :
useradd -d /home/elk -c "Elk main user" -m -s /bin/bash elk passwd elk #donnez lui un vrai mot de passe mkdir /opt/ELK_bin /opt/ELK_data /opt/ELK_logs # effort méritoire pour travailler proprement chown -R elk:elk /opt/ELK_*
Copiez les archives dans /opt/ELK_bin. Au final, vous devez avoir cette liste :
elk@localhost:/opt/ELK_bin$ ls -1 elasticsearch-5.3.0.tar.gz filebeat-5.3.0-linux-x86_64.tar.gz kibana-5.3.0-linux-x86_64.tar.gz logstash-5.3.0.tar.gz metricbeat-5.3.0-linux-x86_64.tar.gz packetbeat-5.3.0-linux-x86_64.tar.gz
Extrayez les toutes, créez les liens symboliques et supprimez les « *.tar.gz ». Et en une seule ligne parce que Unix, quoi…
for f in $(ls -1 *.tar.gz); do echo "--- Working on $f"; g=$(echo $f | cut -d'-' -f1); h=$(echo $f |sed 's/.tar.gz//') ; tar -xzf $f; ln -s $h $g;rm $f; done
« ls -altr » doit vous lister ceci :
packetbeat-5.3.0-linux-x86_64 filebeat-5.3.0-linux-x86_64 metricbeat-5.3.0-linux-x86_64 elasticsearch-5.3.0 kibana-5.3.0-linux-x86_64 logstash-5.3.0 elasticsearch -> elasticsearch-5.3.0 filebeat -> filebeat-5.3.0-linux-x86_64 kibana -> kibana-5.3.0-linux-x86_64 logstash -> logstash-5.3.0 metricbeat -> metricbeat-5.3.0-linux-x86_64 packetbeat -> packetbeat-5.3.0-linux-x86_64
Et voilà : techniquement, vous venez d’installer toute la pile. Vous pourriez la démarrer et faire confiance aux paramètres par défaut, ce serait fonctionnel. Mais nous allons vous montrer où se trouvent les fichiers de configuration et quels sont les principaux paramètres à adapter.
Continuons, si vous le voulez bien (c’est une question purement rhétorique : même si vous êtes totalement libre de changer d’onglet, cet article est si passionnant que vous n’y songerez pas. HEY ! Revenez !).
4) Configuration
Globalement, les fichiers de configuration sont abondamment commentés. Le seul piège étant de bien respecter la syntaxe de YAML et de ne pas s’emmêler dans les niveaux d’imbrication.
De toute façon, en cas d’erreur, le message inscrit dans le log vous indique quoi faire.
- Elasticsearch :
Où ? Dans /opt/ELK_bin/elasticsearch/config/
Quels fichiers ? elasticsearch.yml, jvm.options, log4j2.properties.
« jvm.options » : adaptez « -Xms » et « -Xmx », les bornes de la mémoire pour la JVM (elles sont à 2G par défaut), selon les ressources de votre machine.
« elasticsearch.yml » : donnez un nom à votre cluster et au nœud (« cluster.name » et « node.name »). Indiquez le chemin vers les données (« path.data ») et où stocker les logs (« path.logs »).
Attention ! Si vous modifiez « network.host » pour lui donner une valeur autre que la boucle locale, ElasticSearch considère qu’il n’est plus dans un contexte de test mais dans un vrai cluster. Les avertissements sur les limites systèmes (vm.mx… et nofile) deviennent des erreurs bloquant le démarrage si leurs valeurs ne sont pas celles attendues. Allez relire l’avertissement en début d’article, ça vous apprendra à sauter les sections.
Vous devrez également configurer « discovery.zen.ping.unicast.hosts », qui, à la manière des seeds Cassandra, permet à un nouveau noeud de rejoindre le cluster.
- Kibana
Où ? Dans /opt/ELK_bin/kibana/config/
Quel fichier ? kibana.yml
« server.host » et « server.port » sont à adapter, bien sûr. « server.name » : le nom qui s’affichera sur l’interface de Kibana.
« elasticsearch.url » : le plus important puisqu’il indique où chercher les données.
« kibana.index » : par défaut, les informations propres à Kibana sont stockées dans un index appelé « .kibana ». Vous pouvez le changer mais quel intérêt ? Peut-être pour faire cohabiter plusieurs Kibana piochant dans le même ElasticSearch ?
« elasticsearch.username: « user » » et « elasticsearch.password: « pass » » : renseignez si vous avez activez X-Pack sans nous attendre.
« elasticsearch.requestTimeout: 30000 » : si un serveur de test, nous avons été obligé de monter ce paramètre car les performances ne suffisaient pas vu le volume. En production, cela serait largement suffisant.
« pid.file: /chemin/vers/kibana.pid » : nous vous conseillons de l’activer et de placer ce dossier dans un endroit pratique. Kibana est difficile à trouver par « ps ».
- Logstash
Où ? Dans /opt/ELK_bin/logstash/config/
Quels fichiers ? jvm.options, logstash.yml et un fichier que nous allons créer pour nos besoins et baptiser « central.yml ». Nous y placerons toute notre configuration.
« jvm.options » : comme pour ElasticSearch, adaptez les bornes mémoires aux capacités de votre machine.
« logstash.yml » : rien à modifier pour notre test. Les informations supplémentaires seront inscrites dans le fichier « central.yml ».
« central.yml » : Logstash, au démarrage, accepte un fichier de configuration supplémentaire. Celui-ci se découpe en trois partie : entrée, traitement et sortie. Pour démarrer, nous allons préparer uniquement une section « input » prévue pour Beats et une section « output » pointant vers Elasticsearch et vers la sortie standard (pour faciliter le débogage).
Son contenu :
input {
beats {
port => 5044
}
}
output {
stdout { }
elasticsearch {
hosts => ["machine_noeud1:9200", "machine_noeud2:9200"]
}
}
Normalement, il faudrait une section « filter » pour le traitement des données reçues. Mais nous réservons ça pour une autre fois.
- Beats
Nous pourrions configurer le daemon syslog ou une de ses implémentations (syslogd, rsyslogd…) mais il est plus intéressant d’utiliser les agents collecteurs fournis avec la pile. nous allons configurer MetricBeat sur la machine locale, sachant que tous les Beats fonctionnent sur le même principe.
Où ? /opt/ELK_bin/metricbeat/config/
Quels fichiers ? metricbeat.yml et, indirectement, metricbeat.full.yml
Dans « metricbeat.yml », vous trouverez plusieurs sections clairement délimitées : « Modules configuration », « General », « Output » et « logging ».
« Modules configuration » est la section la plus importante pour la collecte via Metricbeat et demande un peu d’explication : par défaut, vous y trouverez la collect système (« – module: system ») pré-configurée. Vous pourrez cocher / décocher les éléments à remonter ainsi que la fréquence. Mais, à la suite, vous pouvez aussi ajouter d’autres modules comme celui pour MySQL, PostgreSQL, Kafka et bien d’autres, dont des exemples de configuration sont déjà fournis dans le fichier « metricbeat.full.yml ». C’est un système vraiment très pratique.
« General » permet de donner un nom à votre agent et de lui ajouter des étiquettes (« tags ») dès la source. Ainsi, vous pouvez indiquer la machine, l’environnement, le contexte de la collecte : elles seront représentées sous forme de champs dans Elasticsearch/Kibana.
« Output » : les Beats sont configurés pour un envoi vers Elasticsearch mais vous y trouverez également toutes les informations pour Logstash. Commentez « output.elasticsearch: » et dé-commentez « #output.logstash: » puis indiquez les informations de connexion pour Logstash.
Elasticsearch, Logstash, Metricbeat et kibana : nous sommes prêt à démarrer tout cela. Changeons de section !
5) Démarrage
Pour tenter de rester clair malgré la longueur de cet article, nous gardons la même présentation. Ne nous remerciez pas. C’est normal.
- Elasticstack
cd /opt/ELK_bin/elasticsearch ./bin/elasticsearch
Surveillez l’affichage jusqu’à cette ligne :
[2017-04-09T11:16:59,817][INFO ][o.e.n.Node ] [node-1] started [2017-04-09T11:16:59,925][INFO ][o.e.g.GatewayService ] [node-1] recovered [0] indices into cluster_state
Parfait. « ctrl+c » et relancer en mode daemon :
./bin/elaticsearch -d
dans un shell, un test rapide :
curl -XGET 'http://localhost:9200/_stats?pretty'
Affiche :
{
"_shards" : {
"total" : 0,
"successful" : 0,
"failed" : 0
},
"_all" : {
"primaries" : { },
"total" : { }
},
"indices" : { }
}
Ce qui nous montre que tout est correct. Nous pouvons passer à la suite.
- Kibana
L’interface sera lancé en arrière plan et en « nohup ».
cd /opt/ELK_bin/kibana nohup ./bin/kibana &
Dans votre navigateur favori (donc Firefox)(mais ça fonctionne avec les autres), ouvrez « http://127.0.0.1:5601 » et vous devriez voir cet écran :
Kibanaaaaaa (A chanter sur le thème de « Segaaaaa » et savourer la nostlagie)
C’est très beau. Et très vide. Nous y reviendrons plus tard. Occupons nous du reste avant.
- Logstash
cd /opt/ELK_bin/logstash nohup ./bin/logstash -c ./config/central.yml &
« central.yml » : nous vous rappelons que ce nom est un exemple. Vous pouvez appeler votre fichier comme vous le souhaitez (oui, même « comme_vous_le_souhaitez.yml ») tant que la syntaxe qu’il contient est correcte.
A ce sujet, ayant eu l’honneur discutable de tester un grand nombre d’erreurs, nous pouvons vous assurer que le log (situé dans le sous-répertoire « logs » de Logstash) est très clair et vous pointe quasiment à chaque fois le paramètre qui ne lui convient pas.
Note : si le « path.log » n’est pas configuré dans votre logstash.yml, vous trouverez les infos dans le fichier nohup.out.
Prêtez particulièrement attention à ces lignes :
09:35:54.447 [[main]-pipeline-manager] INFO logstash.outputs.elasticsearch - Installing elasticsearch template to _template/logstash
09:35:54.686 [[main]-pipeline-manager] INFO logstash.outputs.elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>[#<URI::Generic:0x50d12073 URL://localhost:9200>]}
09:35:54.694 [[main]-pipeline-manager] INFO logstash.pipeline - Starting pipeline {"id"=>"main", "pipeline.workers"=>4, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>500}
09:35:55.421 [[main]-pipeline-manager] INFO logstash.inputs.beats - Beats inputs: Starting input listener {:address=>"0.0.0.0:5044"}
09:35:55.486 [[main]-pipeline-manager] INFO logstash.pipeline - Pipeline main started
Il y aurait moyen de tester l’insertion Logstash vers ElasticSearch en utilisant le plug-in « STDIN » mais utilisons plutôt le Metricbeat. Une pierre, deux coups, et nous éviterons d’allonger un article déjà trop long. Voyons avec Filebeat et Metricbeat.
- Filebeat
cd /opt/ELK_bin/filebeat nohup ./filebeat -c filebeat.yml &
Le fichier de configuration est très simple à mettre en place : il faut définir une entrée par fichiers à surveiller (« fichiers » au pluriel car la commande est récursive), la sortie (ici, Logstash) et éventuellement des étiquettes supplémentaires. Vous aurez également la possibilité d’exclure certains fichiers, certaines lignes… Bref, c’est puissant.
Hors commentaire, notre « filebeat.yml » se résume à ces quelques lignes :
filebeat.prospectors: - input_type: log paths: - /opt/ELK_bin/*/logs/* exclude_files: [".gz$"] multiline.pattern: ^\[ multiline.negate: false multiline.match: after name: fb_local tags: ["filebeat", "localhost"] output.logstash: hosts: ["localhost:5044"]
Dans le log, vérifiez le bon fonctionnement (et le périmètre) en cherchant la chaîne « INFO Harvester started for file: ». Il y en aura une par fichier surveillé.
- Metricbeat
cd /opt/ELK_bin/metricbeat nohup ./metricbeat -c metricbeat.yml &
Hors commentaires, un fichier de configuration comporte un vingtaine de lignes. Sur notre machine locale, il ressemble à ça :
metricbeat.modules: - module: system metricsets: - cpu - load - filesystem - fsstat - memory - network - process enabled: true period: 10s processes: ['.*'] name: mon_truc_en_crrrr tags: ["TuPeuxPas_Test", "local"] output.logstash: hosts: ["localhost:5044"]
Si nous voulions ajouter une collecte pour MySQL ou pour un autre composant, il suffirait de reprendre le paragraphe dans le fichier « metricbeat.full.yml » et de le coller dans « metricbeat.modules: ». Ci-dessous, la liste des modules fournis par défaut :
– module: system
#- module: apache
#- module: couchbase
#- module: docker
#- module: haproxy
#- module: kafka
#- module: mongodb
#- module: mysql
#- module: nginx
#- module: postgresql
#- module: prometheus
#- module: redis
#- module: zookeeper
Dans le log (situé – vous devez commencer à voir le principe – dans le sous répertoire « logs »), vous verrez ces lignes triomphales :
2017-04-13T10:17:56+02:00 INFO metricbeat start running. 2017-04-13T10:18:26+02:00 INFO Non-zero metrics in the last 30s: fetches.system-cpu.success=3 fetches.system-fsstat.events=3 fetches.system-process.success=3 fetches.system-filesystem.events=116 fetches.system-filesystem.success=3 fetches.system-fsstat.success=3 libbeat.logstash.call_count.PublishEvents=3 libbeat.logstash.publish.write_bytes=72703 fetches.system-network.success=3 libbeat.logstash.published_and_acked_events=934 libbeat.publisher.published_events=934 fetches.system-load.events=3 libbeat.logstash.publish.read_bytes=72 fetches.system-network.events=21 fetches.system-load.success=3 fetches.system-memory.events=3 libbeat.publisher.messages_in_worker_queues=934 fetches.system-cpu.events=3 fetches.system-memory.success=3 fetches.system-process.events=785
« Non-zero metrics » : Metricbeat indique le nombre de valeurs qu’il sait devoir envoyer. Il se base pour cela sur un fichier de suivi , le « registry », qui lui permet de reprendre après interruption. Comme ça, pas de perte de d’information. Tous les beats fonctionnent sur ce modèle.
Petite pause de satisfaction : le premier contact avec ElasticStack est rude car il y a de nombreux termes à assimiler.
Si tout s’est bien passé, et si aucune erreur ne s’est glissée dans cette article, vous devriez avoir tout installé et démarré en moins d’une heure, selon votre niveau.
La seconde fois sera bien plus rapide et les suivantes encore plus. De notre expérience personnelle, ayant eu à reconstruire plusieurs environnements de démonstration, il faut moins de 10 minutes pour une installation locale, avec un seul noeud ElasticSearch et deux Beats, filebeat et metricbeat.
Mais ce n’est que la première partie ! Logstash pour le traitement des données et Kibana pour la génération des rapports vont vous prendre la plus grosse partie de votre temps.
6) Retour à Kibana et première visualisation
Comme annoncé au début cet article (début qui parait si loin, mainenant !), nous allons conclure avec Kibana. Le but est de vous faciliter le premier contact.
Connectez-vous sur l’URL locale de Kibana. Dans notre exemple : http://127.0.0.1:5601.
Vous êtes accueilli par le message « Configure an index pattern » car Kibana doit savoir où chercher les données. Vous allez vous rendre compte du soin apporté à l’aide contextuelle au sein de l’interface : les messages vous préviennent des possibilités et des risques, une aide discrète sous forme de « i » est placée près des points méritant éclaircissement… Cela rend l’utilisation agréable et masque en partie la complexité de l’activité qui nous attend : exploiter les données.
En premier lieu, laissez coché « Index contains time-based events ». « logstash-* » doit déjà être présent dans la case « Index name or pattern « . Il vous reste à choisir un champs dans « Time-field name » – ceux qui sont utilisables vous sont proposés dans la liste déroulante; choisissez « @timestamp » – et vous êtes paré. Cliquez sur « Create » et c’est terminé.
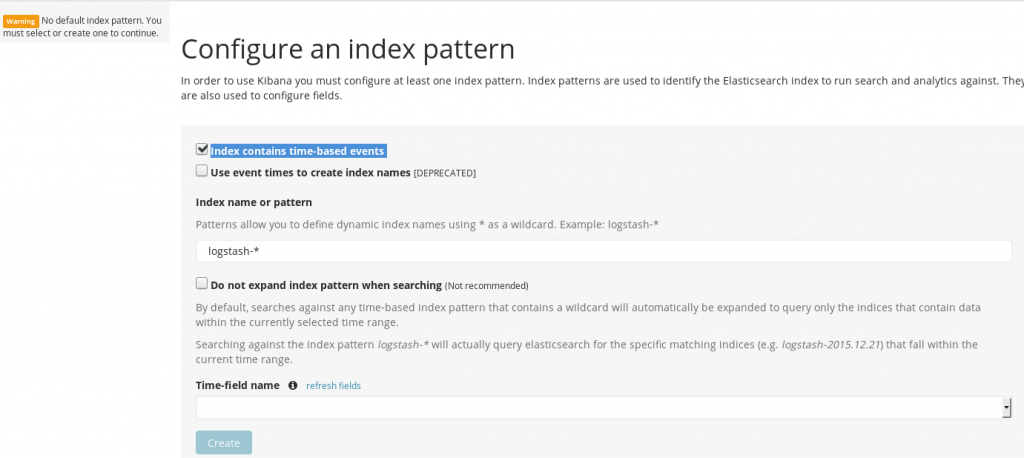
Kibana : page de configuration initiale
L’index par défaut est configuré et Kibana, content de lui, vous redirige vers l’écran de gestion des-dits indexes. Cela dépasse nos ambitions pour aujourd’hui aussi cliquez plutôt sur la section « Discover » du menu de gauche.
Comme vous pourrez le voir : les informations brutes sont disponibles, sous un graphe du nombre d’évènements collectés. Chaque ligne se déplie et vous pouvez cliquer sur les champs pour ajouter leurs valeurs au filtre. Il est possible de choisir précisément les champs à afficher, leur ordre, de les filtrer …
Cependant, cette section vous servira surtout à vous faire une idée de la nature de vos données afin de faciliter l’utilisation de la suivante : la visualisation.
Kibana : visualisation
(Il manque une partie de la liste sur l’image).
Note : si vous parcourez internet à la recherche d’information sur ElasticSearch et Kibana, voici un moyen simple d’estimer la fraîcheur des informations : un bel écran bleuté et harmonieux = Kibana 5, donc article assez frais. Écran noir et marron façon Bauhaus : Kibana 4 donc attention.
Nous allons prendre l’exemple le plus simple possible : un graphique en barre représentant le nombre d’événements par intervalle de temps.
Le chemin pour l’obtenir : « visualize » -> « vertical bar chart ». Sur les ordonnées, par défaut, un comptage des évènements. Pour les abscisses, choisissez la fonction d’agrégation « Date histogram » et laissez-là se débrouiller pour trouver un affichage harmonieux. Cliquez enfin sur la flèche blanche dans le carré bleu, en haut de la colonne, et – ooooooh ! – le graphique s’affiche.
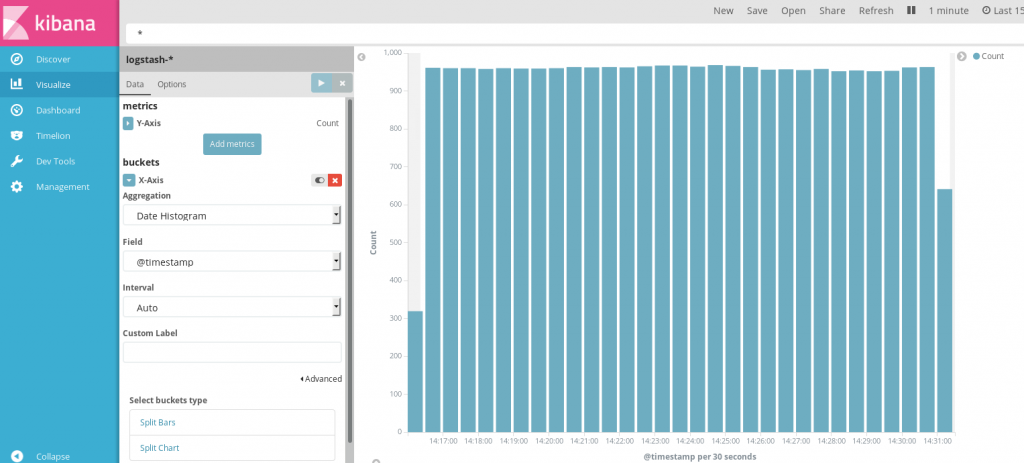
Kibana : exemple d’histogramme
Notre contrat est rempli : vous venez de générer votre premier graphique Kibana et commencé à explorer vos données.
7) Conclusion
A partir de maintenant, si nous avons bien fait notre travail, vous avez tous les éléments en main pour explorer cet outil (cet ensemble d’outils, pour être exact). Sachez que vous pouvez sauvegarder les visualisations et les regrouper dans des tableaux de bord, que vous pourrez également sauvegarder et partager.
Nous avons volontairement laissé de côté le point « X-Pack » car il soulève autant de questions à lui tout-seul que le reste des composants. Nous y reviendrons.
En attendant, profitez bien du fruit de vos efforts : il y aurait encore beaucoup à dire ( la gestion du cluster ElasticSearch, conservation des données, optimisation…) mais il est temps de reposer nos yeux irrités par la conjonctivite du labeur et de l’apprentissage.
Bravo à ceux qui ont eu le courage de nous lire jusqu’ici ! En récompense, une image que les amateurs de journalisme total à l’américaine apprécieront.

Peter Et Steven : Journalistes Totaux et Américains Classieux
Des problèmes ? des questions ? Exprimez-vous ! Les commentaires sont ouverts. Coquilles et fautes de grammaires sont notre lot quotidien : signalez-les nous à m.capello@dbsqware.com